Decompilation without Function ID
One major task of reverse engineering binary code is to identify library code. Because, what the library code does is often known it is of no interest to an analyst. Hex-Rays has developed the IDA F.L.I.R.T. signatures to tackle the problem. Function ID is Ghidra’s function signature system. Unfortunately, for Ghidra there are very few Function ID datasets. There is only function identification for the Visual Studio supplied libraries.
Ghidra already comes with everything you need to automate Function ID dataset generation. In this article I outline how I use Ghidra’s headless analyzer and the Function ID pre- and post-analysis scripts to automatically generate Function ID datasets for the static libraries in the CentOS repositories.
My code: https://github.com/threatrack/ghidra-fid-generator (Research code; so please read this article before trying to use;)
Ghidra’s Function ID allows to automatically identify functions based on hashing the masked1 function bytes.
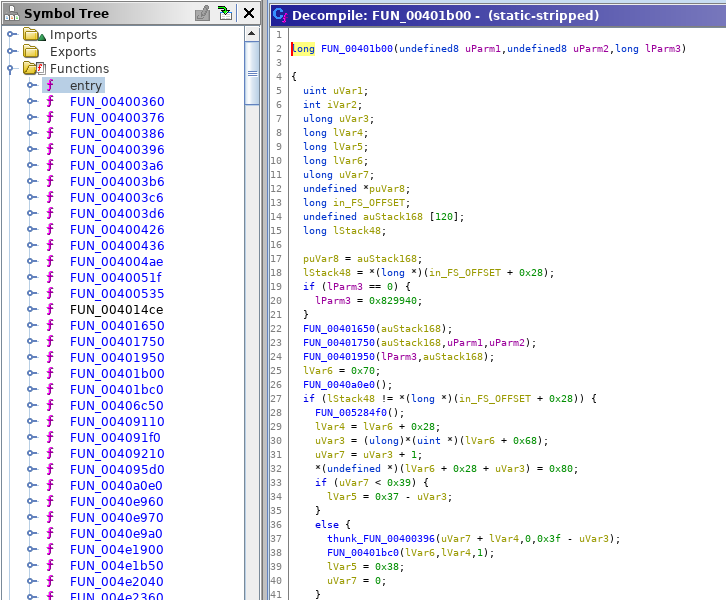
Analyzing a binary that has OpenSSL statically linked may look like:
Decompilation without Function ID
An analyst that wants to know what this code does would need to figure out that some of these functions are functions of OpenSSL by manually analyzing them.
If Ghidra knows the function hashes of the included OpenSSL library it can identify OpenSSL functions as follows:
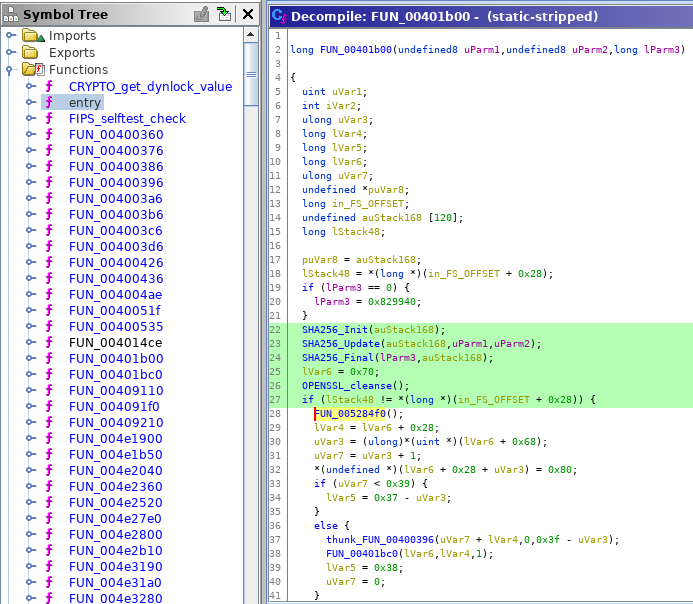
Decompilation with Function ID
A match for a function shows what library matched the function’s hash. In this case it was openssl-static with version 1.0.2k from the 19.el7.x86_64 release:
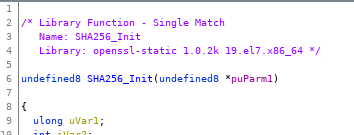
Function ID match
This match is based on a Function ID dataset I automatically generated.
A very quick way to get a large amount of static library code is from Linux repositories. To this end, I started by downloading all RPM packages containing -static- from the CentOS repositories.
This step is fully automated via 00-get-el-rpms.sh.
After running 00-get-el-rpms.sh we have a folder rpms with:
rpms
|-- atlas-static-3.10.1-12.el7.i686.rpm
|-- atlas-static-3.10.1-12.el7.x86_64.rpm
|-- audit-libs-static-2.4.5-6.el6.i686.rpm
|-- audit-libs-static-2.4.5-6.el6.x86_64.rpm
|-- audit-libs-static-2.8.4-4.el7.i686.rpm
[...]
|-- zlib-static-1.2.7-18.el7.i686.rpm
`-- zlib-static-1.2.7-18.el7.x86_64.rpm
0 directories, 462 filesNext, we must unpack the RPMs and extract the object files from the containing library archives (.a).
This step is fully automated via 01-unpack-all-rpm.sh (which calls 01-unpack-rpm.sh).
After running 01-unpack-all-rpm.sh we have a folder el with:
el
|-- el6.i686
| |-- audit-libs-static
| | `-- 2.4.5
| | `-- 6.el6.i686
| | |-- auditd-config.o
| | |-- audit_logging.o
| | |-- auparse.o
[...]
|-- uwsgi-router-static
| `-- 2.0.16
| `-- 1.el7.x86_64
`-- zlib-static
`-- 1.2.7
`-- 18.el7.x86_64
|-- adler32.o
|-- compress.o
[...]
|-- uncompr.o
`-- zutil.o
1231 directories, 154850 filesMore specifically el having the folder structure el{6,7}.{i686,x86_64}/libname/version/release/*.o.
This is the folder structure needed by Ghidra’s CreateMultipleLibraries.java. This script automatically collects the function hashes from a directory structure with the above layout and populates a Function ID dataset with it.
You could now follow $GHIDRA_HOME/Ghidra/Features/FunctionID/data/building_fid.txt and manually import the libraries. However, the large amount of object files calls for full automation.
The full help for the Ghidra headless analyzer is at $GHIDRA_HOME/support/analyzeHeadlessREADME.htm.
02-ghidra-import.sh is automating the import of the above directory structure.
The command is basically:
analyzeHeadless "$GHIDRA_PROJ" el-fidb -import el/el7.x86_64 -recursive \
-preScript FunctionIDHeadlessPrescript.java \
-postScript FunctionIDHeadlessPostscript.java \
-processor x86:LE:64:default -cspec gccThe
analyzeHeadless is the Ghdira headless analysis command (the script will derive this from $GHIDRA_HOME)$GHIDRA_PROJ is your project pathel-fidb is the project that is used (if it does not exist it will be created)-import instructs Ghidra to import programsel/el7.x86_64 is the folder to import (the script will take this as argument so you can import el/el7.i686 for the 32-bit libraries just as easily)-recursive imports the directory structure recursively-preScript FunctionIDHeadlessPrescript.java run this script before analysis-postScript FunctionIDHeadlessPostscript.java run this script after analysis-processor x86:LE:64:default -cspec gcc set the Language ID and Compiler Spec (the script automatically adjusts Language ID based on the given library path)FunctionIDHeadlessPrescript.java and FunctionIDHeadlessPostscript.java are scripts included with Ghidra that disable certain analysis options (such as Function ID) suitable for headless Function ID generation.
After this you should have the el directory structure with all the .o files in the Ghidra el-fidb project.
WARNING: This will take forever!
WARNING: You must use Ghidra 9.1-DEV or later. Earlier versions have a bug with x86_64 relocations.
It is advised that you delete the libraries from el that you don’t need Function ID datasets for to speed up the process. You can run 01-reduce.sh to move all files to el7.{i686,x86_64}.full and only copy a selected set of libraries back to el7.{i686,x86_64}.
For starters I would recommend you make a folder under el where you only have on library, i.e., a directory structure like:
el
`-- el7.x86_64.test
`-- openssl-static
`-- 1.0.2k
`-- 19.el7.x86_64
|-- a_bitstr.o
|-- a_bool.o
|-- a_bytes.o
[...]
|-- x_spki.o
|-- xts128.o
|-- x_val.o
|-- x_x509a.o
`-- x_x509.o
Then run ./02-ghidra-import.sh el/el7.x86_64.test to import the openssl-static 1.0.2k 19.el7.x86_64 library.
Once you have imported a subdirectory from the el directory. We can use ghidra_scripts/AutoCreateMultipleLibraries.java to generate the Function ID dataset. AutoCreateMultipleLibraries.java is a modification of Ghidra’s included CreateMultipleLibraries.java to make it work headless.
03-ghidra-fidb.sh automates the Function ID dataset generation.
The script basically calls:
analyzeHeadless "$GHIDRA_PROJ" el-fidb -noanalysis -scriptPath ghidra_scripts \
-preScript AutoCreateMultipleLibraries.java \
log/duplicate_results.txt true fidb "/el7.x86_64.test" log/common.txt x86:LE:64:default-noanalysis indicates that no default analysis should be performed-scriptPath ghidra_scripts sets the script path to ghidra_scripts-preScript AutoCreateMultipleLibraries.java run our modified script
log/duplicate_results.txt is the first argument to our script. This is the path the CreateMultipleLibraries.java will write information about duplicate functions to.true is the second argument. This indicates that duplicates should be reported (see the unmodified CreateMultipleLibraries.java for details)fidb the folder where the Function ID dataset should be written to./el7.x86_64.test the folder in the Ghidra project for which the Function ID dataset should be generated. This is also the name of the .fidb file generated in the fidb (see previous parameter).log/common.txt list with function names that should be absolutely included in the Function ID dataset (see the unmodified CreateMultipleLibraries.java for details)x86:LE:64:default Language IDWhen you run 03-ghidra-fidb.sh el/el7.x86_64.test (and you followed the previous import instructions for el7.x86_64.test) Ghidra will generate a Function ID dataset as fidb/el7.x86_64.test.fidb that contains the function hashes of the libraries you imported from the el/el7.x86_64.test folder.
For the openssl-static 1.0.2k 19.el7.x86_64 library the generated Function ID dataset is openssl-static-1.0.2k-19.el7.x86_64.fidb.
I will upload more Function ID datasets to Ghidra once the analysis completed.
While running these 4 scripts will (in theory) generate you Function ID datasets for all static libraries available in the CentOS repositories, the generated Function ID datasets are likely not perfect.
$GHIDRA_HOME/Ghidra/Features/FunctionID/data/building_fid.txt mentions using RemoveFunctions.java to remove wrapper functions and other dirt from the generated Function ID dataset. However, that script is Visual Studio library specific. For these CentOS libraries a hand tuned RemoveFunctions.java would be needed to clean up the generated hashes to perfection.
Before distributing the .fidb you should run RepackFid.java to pack the defragment it.
The next steps are to have a full run over the whole CentOS static libraries. (I previously imported lots of libraries. However, I then stumbled on a Ghidra bug rendering the imported data useless.)
The 02-ghidra-import.sh and 03-ghidra-fidb.sh can be modified to work with many different libraries.
If you have a good list of widely used static libraries for Windows or in firmware please contact me, so I can tackle that list next. The CentOS repo case was just a test to familiarize myself with Ghidra headless processing and Function ID dataset generation.
Another worthwhile effort is to run such automated analysis on a server via Ghidra server.
Ghidra masks addresses so the hash is independent from the address of the function.↩